
Python Pandasはデータ分析やデータ操作のための強力なツールです。
データの集計やグループ化、データの選択やフィルタリングなど、
さまざまなデータ処理を簡単に行うことができます。
また、データの読み込みや保存も簡単に出来る便利なツールなので、
データ分析の効率化や洞察の獲得に役立ちます。
ぜひこれらの機能を使って、データ分析に取り組んでみてください。
①Python Pandasとは?

Pandasはデータ操作と分析のための強力なライブラリです。
Pythonで広く使われており、データのクリーニング、変換、集約、可視化など、
様々なデータ処理を効率的に実行できます。
Pandasの使い方をマスターすることで、データサイエンスや機械学習の分野で役立ちます。
Pandasの概要と特徴
Python Pandasはデータ操作と分析のための強力なツールです。
データフレームと呼ばれる表形式のデータ構造を作成し、
データの選択、フィルタリング、ソート、結合などの操作を簡単に行うことができます。
また、欠損データの処理や集約、グループ化、可視化など、
さまざまな機能が組み込まれています。
Python Pandasの特徴は扱いやすさと柔軟性にあります。
直感的なAPI設計により、初心者から上級者まで幅広いユーザーが利用できます。
さらに、多様なデータ形式やデータ構造に対応しており、
データのクリーニングや変換、集約、可視化などのニーズに柔軟に対応することができます。
高速なデータ処理とパフォーマンスも魅力の一つであり、
大規模なデータセットに対しても効率的に処理することができます。
Pandasの主な用途と利点
Python Pandasは、多岐に渡るデータ操作と分析の用途で幅広く利用されています。
まず、データのクリーニングと前処理においては
欠損値の処理や重複データの除去、異常値の検出など、
データの品質を向上させるための作業に活用されます。
これにより、信頼性の高いデータを分析の基盤として用いることができます。
また、データの操作と変換においては
データの選択、フィルタリング、ソート、結合などの操作を柔軟に行うことができます。
データフレームを用いたデータの変形や集約、グループ化なども簡単に行えるため、データの加工や集計を効率的に行うことができます。
さらに、データの可視化においてはPython Pandasはグラフやプロットを作成するための機能を提供しています。
データのパターンや相関関係を視覚的に理解するための強力なツールとなっています。
Python Pandasの利点はその扱いやすさにあります。
初心者でも使いやすく、豊富な機能と最適化された処理手法により、データ分析のプロセスを効率化することができるので他のデータサイエンスライブラリや機械学習ツールとの統合もスムーズです。
②Python Pandasのインストール方法

Python Pandasを利用するためには、まず正しくインストールする必要があります。以下では、Anacondaとpipを使用したインストール方法について説明します。
Anacondaを使用したインストール
Anacondaを使用するとPython Pandasを含むデータサイエンス向けのパッケージが
一括でインストールされます。
Anacondaのインストール方法は下の記事を参考にしてください。
-


-
【すぐに使える】AnacondaでPythonをインストールする方法
『Pythonに興味がある』、『業務を自動化したい』でも、どうやってインストールするの? 東証プライム上場企業のメーカ開発職で、業務やツイッター運用などで約2年ほどPythonを使用した僕がPytho ...
続きを見る
Anacondaをインストールしたらターミナルに以下のコマンドを入力します。
conda install pandasコマンドを実行すると、Python Pandasがインストールされます。
pipを使用したインストール
pipを使用したPython Pandasをインストール方法を紹介します。
以下のコマンドを入力します。
pip install pandasマンドを実行するとPython Pandasがpipを通じてインストールされます。
インストールが完了したら正しく動作するかを確認するため、
PythonやJupyter Notebookなどで、以下のコードを実行してみましょう。
import pandas as pd
print(pd.__version__)バージョン番号が表示されれば、Python Pandasのインストールは成功しています。
これで、データフレームの作成と基本操作に進む準備が整いました。
③データフレームの作成と基本操作

Python Pandasではデータを扱うための中心的なデータ構造として
「データフレーム」を提供しています。
ここでは、データフレームの作成と基本的な操作方法について以下の内容で説明します。
- データフレームの作成方法
- インデックスとカラムの操作
- データの参照
- データの追加と削除
データフレームの作成方法
データフレームを作成するには、さまざまな方法があります。
最も一般的な方法は、辞書やリストを用いてデータを定義し、
それをデータフレームに変換する方法です。
以下は例です。
辞書を用いたデータフレームの作成
import pandas as pd
# 辞書を用いたデータフレームの作成
data = {'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'Country': ['Japan', 'USA', 'Canada']}
df = pd.DataFrame(data)
print(df)# 実行結果
Name Age Country
0 Alice 25 Japan
1 Bob 30 USA
2 Charlie 35 Canadaリストを用いたデータフレームの作成
import pandas as pd
# リストを用いたデータフレームの作成
names = ['Alice', 'Bob', 'Charlie']
ages = [25, 30, 35]
countries = ['Japan', 'USA', 'Canada']
df = pd.DataFrame({'Name': names, 'Age': ages, 'Country': countries})
print(df)# 実行結果
Name Age Country
0 Alice 25 Japan
1 Bob 30 USA
2 Charlie 35 Canada当然ですが辞書、リストどちらを使っても同じ結果が出力されます。
好みで使い分けてもらえば大丈夫です。
あと、覚えてほしいのが以下の関係です。
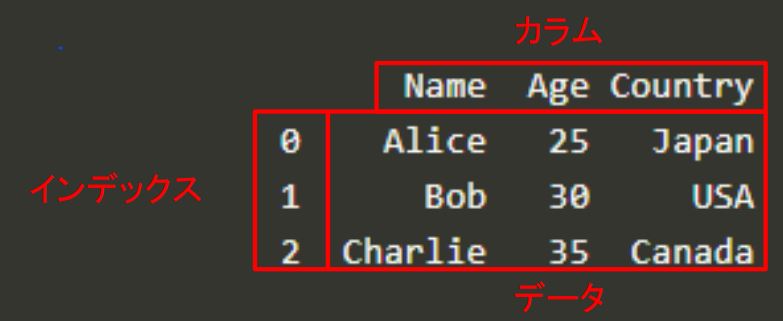
カラムが列の名前、インデックスが行の名前と覚えましょう。
インデックスとカラムの操作
データフレームではデータに対してインデックスとカラムを指定することができます。
インデックスはデータの行を識別するためのラベルであり、
カラムはデータの列を識別するためのラベルです。
以下は、インデックスとカラムの操作方法の例です。
import pandas as pd
data = {'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'Country': ['Japan', 'USA', 'Canada']}
df = pd.DataFrame({'Name': names, 'Age': ages, 'Country': countries})
# インデックスの指定
df = pd.DataFrame(data, index=['A', 'B', 'C'])
# カラムの指定
df = pd.DataFrame(data, columns=['Name', 'Age', 'Country'])
# カラムの追加
df['Gender'] = ['Female', 'Male', 'Male']
# カラムの削除
df = df.drop('Country', axis=1)# 実行結果
# インデックスの指定
Name Age Country
A Alice 25 Japan
B Bob 30 USA
C Charlie 35 Canada
# カラムの指定
Name Age Country
0 Alice 25 Japan
1 Bob 30 USA
2 Charlie 35 Canada
# カラムの追加
Name Age Country Gender
0 Alice 25 Japan Female
1 Bob 30 USA Male
2 Charlie 35 Canada Male
# カラムの削除
Name Age Gender
0 Alice 25 Female
1 Bob 30 Male
2 Charlie 35 Maleデータの参照
データフレーム内の特定のデータや部分データにアクセスするためには、データの参照が利用されます。
以下は、データの参照例です。
import pandas as pd
names = ['Alice', 'Bob', 'Charlie']
ages = [25, 30, 35]
countries = ['Japan', 'USA', 'Canada']
df = pd.DataFrame({'Name': names, 'Age': ages, 'Country': countries})
# 特定のカラムのデータを参照
names = df['Name']
print(names)
# 特定の行のデータを参照
row = df.loc[0]
print(row)
# 複数のカラムのデータを参照
subset = df[['Name', 'Age']]
print(subset)
# 複数の行のデータを参照
subset = df.loc[[0, 1]]
print(subset)
# 条件を満たすデータを参照
subset = df[df['Age'] > 30]
print(subset)# 実行結果
# 特定のカラムのデータを参照
0 Alice
1 Bob
2 Charlie
# 特定の行のデータを参照
Name Alice
Age 25
Country Japan
# 複数の行のデータを参照
Name Age Country
0 Alice 25 Japan
1 Bob 30 USA
# 複数のカラムのデータを参照
Name Age
0 Alice 25
1 Bob 30
2 Charlie 35
# 条件を満たすデータを参照
Name Age Country
2 Charlie 35 Canadaデータの追加と削除
データフレームにはデータを追加したり削除したりする方法もあります。
以下は、データの追加と削除の例です。
import pandas as pd
names = ['Alice', 'Bob', 'Charlie']
ages = [25, 30, 35]
countries = ['Japan', 'USA', 'Canada']
df = pd.DataFrame({'Name': names, 'Age': ages, 'Country': countries})
# 行の追加
new_row = {'Name': 'Dave', 'Age': 40, 'Country': 'Australia'}
df = df.append(new_row, ignore_index=True)
# 列の追加
df['City'] = ['Tokyo', 'New York', 'Toronto', 'Sydney']
# 行の削除
df = df.drop(0)
# 列の削除
df = df.drop('City', axis=1)# 実行結果
# 行の追加
Name Age Country
0 Alice 25 Japan
1 Bob 30 USA
2 Charlie 35 Canada
3 Dave 40 Australia
# 列の追加
Name Age Country City
0 Alice 25 Japan Tokyo
1 Bob 30 USA New York
2 Charlie 35 Canada Toronto
3 Dave 40 Australia Sydney
# 行の削除
Name Age Country City
1 Bob 30 USA New York
2 Charlie 35 Canada Toronto
3 Dave 40 Australia Sydney
# 列の削除
Name Age Country
1 Bob 30 USA
2 Charlie 35 Canada
3 Dave 40 AustraliaPandasを使ったデータフレームについて解説しました。
データフレームの読込みや保存についての記事をかいたので参考にしてください。
-

-
PandasでCSV・エクセルデータを読込と保存!
データの扱いにおいて、CSVやエクセルは広く利用されるフォーマットです。しかし、そのデータを効果的に読み書きすることは簡単ではありません。 そこで登場するのがPythonのPandasです。 Pand ...
続きを見る
今回は以上です。
{kind=link}