
データをわかりやすく伝えるためにSeabornを使いませんか?
Seabornを使えばグラフやプロットを簡単に作成し、
魅力的な視覚表現を実現することができます。
データの可視化はただ数字をグラフにするだけではありません。
散布図やヒストグラム、箱ひげ図など、さまざまなグラフを通じて
データの傾向やパターンを見つけ出すことができます。
記事では、具体的なプログラムの書き方や様々なグラフの作成手法を解説しています。
データの可視化によって、分析結果をわかりやすく伝えることができるでしょう。
①Seabornの概要と基本知識

Seabornについて以下の内容で解説します。
- Seabornとは何か?
- Seabornの主な特徴と利点
Seabornとは何か?
SeabornはPythonのデータ可視化ライブラリで、美しいグラフを簡単に作成できます。
Matplotlibに基づいており、統計グラフやデータ可視化に特化した機能を持っています。
Seabornの主な特徴と利点
Seabornの特徴として美しいデフォルトのスタイルとカラーパレット、
簡単なコードと豊富なカスタマイズオプションです。
また、Pandasデータフレームとの統合もスムーズなので直感的な操作が可能です。
②Seabornの基本的な使用方法

Seabornの基本的な使用方法について以下の内容で解説します。
- Seabornのインストール方法
- 散布図と回帰曲線の描画
- ヒストグラムとカーネル密度推定の可視化
- バーとカウントプロットの作成
- 箱ひげ図とバイオリンプロット
Seabornのインストール方法
Seabornをインストールするには、Pythonのパッケージ管理ツールであるpipを使用します。
以下のコマンドを実行してください。
pip install seaborn散布図と回帰曲線の描画
散布図の作成
散布図はデータの相関関係や分布を視覚的に表現するグラフです。
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
# データの準備
data = pd.DataFrame({'Height': [160, 165, 170, 175, 180],
'Weight': [50, 55, 60, 65, 70]})
# 散布図を表示
sns.scatterplot(data=data, x='Height', y='Weight')
plt.title("Height vs Weight")
plt.xlabel("Height (cm)")
plt.ylabel("Weight (kg)")x軸に身長、y軸に体重をプロットするグラフを描画しようと思います。
身長と体重のデータを含むDataFrameを作成します。
ここでは身長の列を'Height'、体重の列を'Weight'として指定し、
5人のデータを用意しています。
その後、sns.scatterplot関数を使用して散布図を作成します。data引数には先ほど作成したDataFrameを指定し、x引数とy引数にはそれぞれ身長と体重の列の名前を指定します。
プログラムを実行すると、身長と体重の関係を散布図として表示することができます。
plt.title、plt.xlabel、plt.ylabel関数を使用して
それぞれタイトルや軸ラベルを指定することができます。
回帰曲線の追加
回帰曲線(Regression Line)は散布図上のデータ点の傾向を表す直線で、
回帰分析によって得られた予測モデルを元に、データの傾向を表現した直線です。
回帰曲線は、散布図上のデータの傾向や関係性を視覚的に把握するために使用されます。
import seaborn as sns
import matplotlib.pyplot as plt
# データの準備
x = [1, 2, 3, 4, 5]
y = [2, 6, 6, 8, 10]
# 散布図と回帰曲線の表示
sns.regplot(x=x, y=y)
# グラフのタイトルと軸ラベルの追加
plt.title("Scatter plot with regression line")
plt.xlabel("Xaxis")
plt.ylabel("Yaxis")
# プロットの表示
plt.show()上記のプログラムでは、xとyに散布図のデータを準備しています。
その後、sns.regplot関数を使用して散布図に回帰曲線を追加しています。
さらに、plt.title関数でグラフのタイトルを設定し、
plt.xlabelとplt.ylabel関数でx軸とy軸のラベルを設定しています。
このプログラムを実行すると、散布図に回帰曲線が表示されます。
データに合わせてxとyを適切なデータに置き換え、
タイトルと軸ラベルを適切なテキストに変更してください。
散布図行列の作成
散布図行列(Scatter Plot Matrix)は
複数の数値変数の間の相関関係や分布を可視化するためのグラフです。
Seabornを使用して散布図行列を作成する方法は以下の通りです。
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
# データの準備
data = pd.DataFrame({'Height': [160, 165, 170, 175, 180],
'Weight': [50, 55, 60, 65, 70],
'Age': [25, 30, 35, 40, 45]})
# 散布図行列を表示
sns.pairplot(data)
# グラフの表示
plt.show()上記のコードでは、Height、Weight、Ageの3つの数値変数を持つデータフレームを作成し、
sns.pairplot()関数を使用して散布図行列を作成しています。
pairplot()関数は、データフレームの各数値変数の組み合わせに対して散布図を作成し、
対角線上にはヒストグラムが表示されます。
plt.show()を使用してグラフを表示することで、散布図行列が描画されます。
散布図行列を通じて、各変数の相関関係や分布の形状を一度に把握することができます。
ヒストグラムとカーネル密度推定の可視化
ヒストグラムの作成
ヒストグラムはデータを一定の区間に分割し、
それぞれの区間に含まれるデータの個数を表現するグラフです。
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
# データの準備
data = pd.DataFrame({'Value': [2, 3, 5, 4, 6, 3, 4, 5, 4, 3, 2, 6, 4, 5]})
# ヒストグラムとカーネル密度推定の可視化
sns.histplot(data=data, x='Value')
plt.title("Histogram")
plt.xlabel("Xaxis")
plt.ylabel("yaxis")
plt.show()上記のコードではdataというDataFrameにヒストグラムを作成するためのデータを用意しています。データはValueという列に格納されており、これをヒストグラムで可視化します。
sns.histplot()関数を使用して、dataを指定し、
x引数にはヒストグラムを作成したい列の名前を指定します。
この場合、Value列を指定しています。
plt.title()関数を使用して、グラフのタイトルを設定します。ここでは、Histogramというタイトルを指定しています。
plt.xlabel()関数を使用して、x軸とy軸ラベルを設定します。
最後にplt.show()を呼び出すことで、作成したヒストグラムが表示されます。
カーネル密度推定の追加
カーネル密度推定(Kernel Density Estimation)は
与えられたデータの分布を滑らかな確率密度関数(カーネル)で推定する統計的手法です。
データの分布をヒストグラムなどの離散的なデータ点ではなく、
連続的な確率密度関数で表現することができます。
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
# データの準備
data = pd.DataFrame({'Value': [2, 3, 5, 4, 6, 3, 4, 5, 4, 3, 2, 6, 4, 5]})
# ヒストグラムとカーネル密度推定の可視化
sns.histplot(data=data, x='Value', kde=True)
plt.title("Histogram with kernel density estimation")
plt.xlabel("Xaxis")
plt.ylabel("yaxis")
plt.show()kde=Trueとするだけでカーネル密度推定を実行できます。
バーとカウントプロットの作成
垂直バープロットの作成
垂直バープロット(Vertical Bar Plot)はデータの頻度やカテゴリごとの数値を
垂直なバー(縦棒)で可視化する方法です。
各バーの高さがデータの値やカテゴリの出現回数を表します。
垂直バープロットは、主に以下のような情報を視覚的に表現するために使用されます:
・カテゴリごとの頻度や数値の比較
・カテゴリごとの出現回数や割合の表示
・データの分布やパターンの可視化
垂直バープロットはカテゴリごとのデータの相対的な大小や比較を
簡単に把握することができます。
さらに、バーの色やラベル、軸の範囲などを調整することで、
情報の強調や視認性の向上が可能です。
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
# データの準備
data = pd.DataFrame({'Category': ['A', 'B', 'C', 'D'],
'Value': [10, 15, 8, 12]})
# 垂直バープロットの作成
sns.barplot(data=data, x='Category', y='Value')
plt.title("Vertical bar plot")
plt.xlabel("Category")
plt.ylabel("Value")
plt.show()上記のコードでは、
dataというDataFrameに垂直バープロットを作成するためのデータを用意しています。
Category列にはカテゴリのラベル、Value列には各カテゴリの値が格納されています。
sns.barplot()関数を使用して、dataを指定し、x引数にはカテゴリの列名を、
y引数には値の列名を指定します。
この場合、Categoryをx軸に、Valueをy軸に設定しています。
plt.title()関数を使用してグラフのタイトルを設定します。
plt.xlabel()関数とplt.ylabel()関数を使用して、x軸とy軸のラベルを設定します。
最後にplt.show()を呼び出すことで、作成した垂直バープロットが表示されます。
水平バープロットの作成
水平バープロット(Horizontal Bar Plot)はデータの頻度やカテゴリごとの数値を
水平なバー(横棒)で可視化する方法です。
水平バープロットでは、各バーの長さがデータの値やカテゴリの出現回数を表し、バーの配置や間隔によってデータのグループやカテゴリを区別します。
水平バープロットは、主に以下のような情報を視覚的に表現するために使用されます。
・カテゴリごとの頻度や数値の比較
・カテゴリごとの出現回数や割合の表示
・データのランキングや並び替えの可視化
水平バープロットは垂直バープロットと比較して
カテゴリのラベルや値の表示がより読みやすくなる場合があります。
特に、カテゴリの名前が長い場合や、値の範囲が広い場合に有用です。
また、水平バープロットはデータのランキングや優先度の表示にも適しており、
データのパターンや傾向を視覚的に把握するのに役立ちます。
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
# データの準備
data = pd.DataFrame({'Category': ['A', 'A', 'B', 'A', 'C', 'B', 'B', 'C', 'B']})
# 水平バープロットの作成
sns.countplot(data=data, y='Category')
plt.title("Horizontal bar plot")
plt.xlabel("Count")
plt.ylabel("Category")
plt.show()垂直バープロットとほとんど同じプログラムです。
sns.countplot()関数を使用して、dataを指定し、y引数にはカテゴリの列名を指定します。この場合、Categoryをy軸に設定しています。
このコードにより、各カテゴリの出現回数をカウントして、
水平バーとして表示するプロットが作成されます。
グラフのタイトルや軸のラベルを設定することで、
可視化結果の理解や読みやすさが向上します。
箱ひげ図とバイオリンプロット
箱ひげ図の作成
箱ひげ図(box plot)はデータの分布や統計的な特徴を視覚化するための図です。
データの中央値、四分位範囲、外れ値などを表現します。
箱ひげ図は以下の要素で構成されます。
箱(box):
データの中央値(median)を中心に、
データの25パーセンタイル(第1四分位数)と75パーセンタイル(第3四分位数)を
示す箱状の領域です。箱の高さはデータの範囲の中央50%を表します。
線(whisker):
箱から延びる線で、データの範囲を示します。
通常、最小値から1.5倍の四分位範囲までの範囲内のデータを含みます。
外れ値はこの範囲外のデータ点として表示されることがあります。
外れ値(outlier):
線の外側に存在する異常な値です。
データの分布から大きく外れた値を示す場合に表示されます。
箱ひげ図は異なるカテゴリやグループのデータを比較する場合や、
データの分布や異常値を視覚化する場合によく使用されます。
中央値や四分位範囲によってデータの中心傾向やばらつきを把握しやすく、
外れ値の存在も可視化されるため、データの特徴を簡潔に理解するのに役立ちます。
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
# データの準備
data = pd.DataFrame({'Category': ['A', 'A', 'B', 'B', 'C', 'C', 'C'],
'Value': [10, 15, 20, 25, 30, 35, 40]})
# 箱ひげ図の作成
sns.boxplot(data=data, x='Category', y='Value')
plt.title('Box plot')
plt.xlabel('Category')
plt.ylabel('Value')
# グラフの表示
plt.show()このプログラムはカテゴリごとに異なる値を持つデータを用いて箱ひげ図を作成しています。
sns.boxplot()関数を使用してデータフレームの列を指定し、xにカテゴリ列、yに値の列を指定します。その後、plt.title()、plt.xlabel()、plt.ylabel()を使用して
グラフのタイトルや軸ラベルを設定します。
最後にplt.show()を呼び出してグラフを表示します。
このプログラムを実行すると、指定したデータに基づいて箱ひげ図が生成され、
カテゴリごとの値の分布や中央値、四分位数、外れ値などが可視化されます。
バイオリンプロットの作成
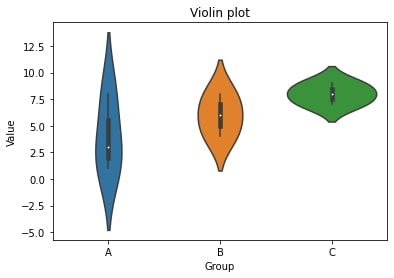
バイオリンプロット(violin plot)はデータの分布と箱ひげ図を組み合わせた視覚化手法です。
データの分布をカーネル密度推定によって表現し、
箱ひげ図の要素として中央値、四分位範囲、外れ値も同時に表示します。
バイオリンプロットは以下の要素で構成されます:
中央の太い縦線(中央の箱ひげ図):
データの中央値と四分位範囲を表します。
箱ひげ図と同様に、データの中心傾向とばらつきを示します。
カーネル密度推定の曲線(バイオリンの形状):
データの分布を表現するためにカーネル密度推定を用いた曲線です。
データの頻度や密度を視覚的に表現し、分布の形状やピークの位置を示します。
バイオリンプロットは箱ひげ図よりも詳細なデータの分布を可視化することができます。
データの密度情報を提供するため、分布の偏りや尖り具合、
多峰性などを把握するのに役立ちます。
また、カテゴリやグループごとのデータの比較や、異なる変数の分布の比較にも使用されます。
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
# データの準備
data = pd.DataFrame({'Group': ['A', 'A', 'A', 'B', 'B', 'B', 'C', 'C', 'C'],
'Value': [1, 8, 3, 4, 8, 6, 7, 8, 9]})
# バイオリンプロットの作成
sns.violinplot(data=data, x='Group', y='Value')
# グラフのタイトルと軸ラベルを設定
plt.title("Violin plot")
plt.xlabel("Group")
plt.ylabel("Value")
# プロットの表示
plt.show()pandasのDataFrameオブジェクトとして用意し、x軸にはグループのカテゴリ変数を、y軸には数値変数を指定しています。sns.violinplot関数を使用してバイオリンプロットを作成します。
③Seabornのカスタマイズ

Seabornのカスタマイズ方法について以下の内容で解説します。
- 凡例と注釈の設定
- プロットのサイズとスケーリングの調整
- スタイルの変更
凡例と注釈の設定
凡例の追加と位置の設定
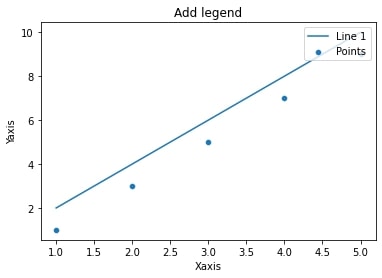
下記はseabornを使用してグラフに凡例を追加し、位置を設定するプログラムです。
import seaborn as sns
import matplotlib.pyplot as plt
# データの作成
x_data = [1, 2, 3, 4, 5]
y_data1 = [2, 4, 6, 8, 10]
y_data2 = [1, 3, 5, 7, 9]
# グラフの描画
sns.lineplot(x=x_data, y=y_data1, label="Line 1")
sns.scatterplot(x=x_data, y=y_data2, label="Points")
# グラフのタイトルと軸ラベルの設定
plt.title("Add legend") # グラフのタイトル
plt.xlabel("Xaxis") # x軸のラベル
plt.ylabel("Yaxis") # y軸のラベル
# 凡例の設定と表示
plt.legend(loc="upper right") # 凡例の位置を右上に設定
# グラフの表示
plt.show()このプログラムはx_dataとy_data1から線グラフを描画し、
x_dataとy_data2に基づいて散布図を描画しています。
各要素にはlabelパラメータを設定し、凡例に表示するラベルを指定しています。
plt.legend()関数を使用して凡例の位置を指定し、plt.show()関数でグラフを表示します。
このプログラムを実行すると右上に凡例を追加されたグラフが表示されます。
注釈の追加
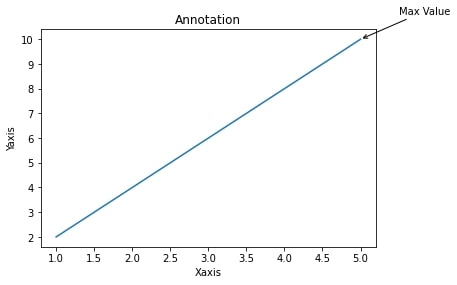
下記はグラフに注釈を追加するプログラムです。
import seaborn as sns
import matplotlib.pyplot as plt
# データの作成
x_data = [1, 2, 3, 4, 5]
y_data = [2, 4, 6, 8, 10]
# グラフの描画
sns.lineplot(x=x_data, y=y_data)
# 注釈の追加
annotation_text = "Max Value"
max_value_index = y_data.index(max(y_data))
max_value_x = x_data[max_value_index]
max_value_y = y_data[max_value_index]
plt.annotate(annotation_text, xy=(max_value_x, max_value_y), xytext=(max_value_x + 0.5, max_value_y + 1),
arrowprops=dict(facecolor='black', arrowstyle='->'))
# グラフのタイトルと軸ラベルの設定
plt.title("Annotation") # グラフのタイトル
plt.xlabel("Xaxis") # x軸のラベル
plt.ylabel("Yaxis") # y軸のラベル
# グラフの表示
plt.show()このプログラムではx_dataとy_dataに基づいて線グラフを描画し、
最大値に対して注釈を追加しています。
注釈のテキストは "Max Value" とし、最大値の位置に矢印付きの注釈を表示しています。
注釈の座標は、最大値のインデックスを取得してx座標とy座標を決定しています。
プログラムを実行するとグラフに線グラフが描画され、
最大値に対して注釈が追加されたグラフが表示されます。
プロットのサイズとスケーリングの調整
プロットのサイズ変更
グラフのサイズを変更するにはplt.figure()関数を使用します。
以下にプロットのサイズを変更するためのコードを示します。
import seaborn as sns
import matplotlib.pyplot as plt
# データの作成
x_data = [1, 2, 3, 4, 5]
y_data = [2, 4, 6, 8, 10]
# 図のサイズを変更
plt.figure(figsize=(8, 6)) # 幅 8インチ、高さ 6インチ
# グラフの描画
sns.lineplot(x=x_data, y=y_data)
# グラフのタイトルと軸ラベルの設定
plt.title("Plot resize") # グラフのタイトル
plt.xlabel("Xaxis") # x軸のラベル
plt.ylabel("Yaxis") # y軸のラベル
# グラフの表示
plt.show()上記の例ではplt.figure(figsize=(8, 6))で図の幅を8インチ、高さを6インチに設定していますが、
必要に応じてサイズを調整してください。
プロットのスケーリングと範囲の設定
グラフのプロットのスケーリングと範囲を設定するにはplt.xlim()とplt.ylim()関数を使用します。以下にスケーリングと範囲の設定方法の例を示します。
import seaborn as sns
import matplotlib.pyplot as plt
# データの作成
x_data = [1, 2, 3, 4, 5]
y_data = [2, 4, 6, 8, 10]
# グラフの描画
sns.lineplot(x=x_data, y=y_data)
# x軸のスケーリングと範囲の設定
plt.xlim(0, 6) # x軸の範囲を0から6までに設定
# y軸のスケーリングと範囲の設定
plt.ylim(0, 12) # y軸の範囲を0から12までに設定
# グラフのタイトルと軸ラベルの設定
plt.title("Setting plot scaling and limits") # グラフのタイトル
plt.xlabel("Xaxis") # x軸のラベル
plt.ylabel("Yaxis") # y軸のラベル
# グラフの表示
plt.show()上記の例ではplt.xlim()を使用してx軸の範囲を0から6までに設定しています。
同様に、plt.ylim()を使用してy軸の範囲を0から12までに設定しています。
プログラムを実行すると指定した範囲で
x軸とy軸がスケーリングされたグラフが表示されます。
軸とy軸のスケーリングと範囲を設定することで、
表示したいデータの範囲や縮尺を調整することができます。
スタイルの変更
スタイルの変更
グラフのスタイルを変更するにはsns.set_style()関数を使用します。この関数を呼び出し、引数として使用したいスタイル名を指定します。以下にスタイルを変更するためのプログラム例を示します。
import seaborn as sns
import matplotlib.pyplot as plt
# データの作成
x_data = [1, 2, 3, 4, 5]
y_data = [2, 4, 6, 8, 10]
# スタイルの変更
sns.set_style("darkgrid") # "darkgrid"スタイルを使用
# グラフの描画
sns.lineplot(x=x_data, y=y_data)
# グラフのタイトルと軸ラベルの設定
plt.title("Change style") # グラフのタイトル
plt.xlabel("Xaxis") # x軸のラベル
plt.ylabel("Yaxis") # y軸のラベル
# グラフの表示
plt.show()上記の例では、sns.set_style("darkgrid")を使用してグラフのスタイルを
"darkgrid" に変更しています。
他にも、"whitegrid"、"dark"、"white"、"ticks" などのスタイルを指定することができます。
プログラムを実行すると、指定したスタイルが適用されたグラフが表示されます。
グラフのスタイルを変更することで、
背景色、グリッドの表示、線のスタイルなどの外観をカスタマイズすることができます。
本記事ははSeabornを使ったデータの可視化を効率的かつ
魅力的に行うためのツールを紹介しました。
その豊富な機能とカスタマイズ性により、
データ分析のプロセスをさらに洗練させることができます。
データを視覚化する際にはぜひSeabornを活用して、
分かりやすく魅力的なグラフを作成してみてください。
今回は以上です。
{kind=link}