
以前に『スクレイピングで出来ることと注意点』という記事で
スクレイピングについて紹介しました。
-


-
【必読】Pythonでスクレイピング!出来ることと注意点!
以前に『Python出来ること5選』という記事でスクレイピングについて紹介しました。 『Pythonを使えばスクレイピングが可能で、サイトから自動で情報を取得できることは分かったが、他に何かできるの? ...
続きを見る
スクレイピングについて十分理解できたと思うので、
今回はPythonのseleniumを使ったスクレイピング方法について解説します。
①Pythonのseleniumでスクレイピングする前にやるべきこと。

SeleniumはWebDriverを使ってブラウザを操作(サイトにログインなど)して
必要な情報を取得します。
なのでWebDriverのインストールが必要となります。
今回は僕が普段使っている便利なChromeDriverの解説をします。
Pythonのseleniumでスクレイピングする前にやるべきことを以下の順序で説明します。
Pythonのseleniumでスクレイピングする前にやるべきこと。
- 1.chrome driverをダウンロード
- 2.seleniumをインストール
手順1:chrome driverをダウンロード
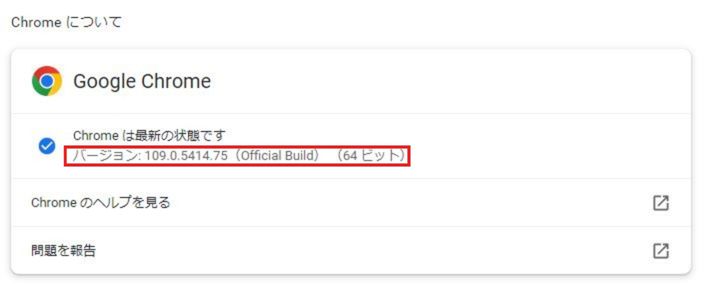
Chromeのバージョン確認はChromeを開き、『設定』→『Chromeについて』から確認できます。
僕が使ってるChromeのバージョンは『109.0.5414.75』で、
後に使うのでメモしましょう!
次はChromeDriverのインストールで、
下のリンクからダウンロードします。
ChromeDriver
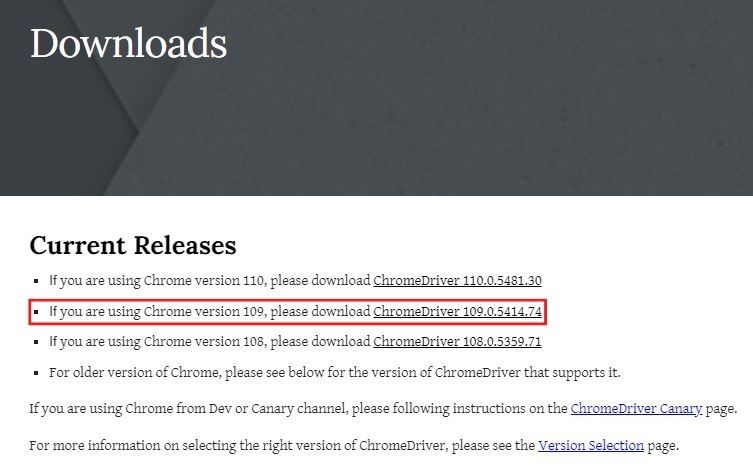
Chromeのバージョンは『109』だったので、
赤枠をクリックします。
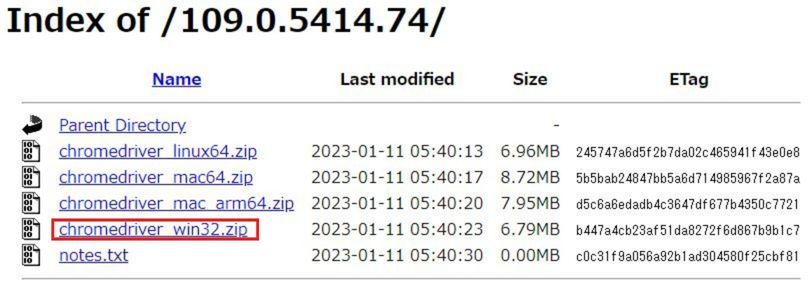
Windowsユーザの方は『chromedriver_win32.zip』をダウンロード後に解凍します。
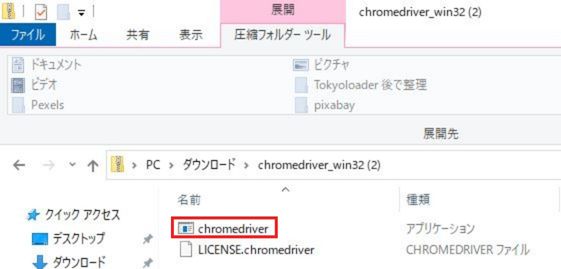
解凍後は『chromedriver』が保存されていることを確認し、
任意の場所に移動してもらって大丈夫ですがPythonのプログラム内で
『chromedriver』のディレクトリを指定するので、メモを取りましょう!
手順2:seleniumをインストール
pip install seleniumpip install seleniumでモジュールをインストールしましょう。
これで準備が整いました。
②seleniumの使い方

次は具体的な使い方を以下の手順で解説します。
seleniumの使い方
- 1.Google chromeを起動させてみる
- 2.要素を取得する
- 3.要素を操作する
手順1:Google chromeを起動させてみる
まずは簡単な操作としてGoogleのページを表示して5秒後に閉じる操作を実行してみます。
コードは下を参考にして下さい。
from selenium import webdriver
from time import sleep
# 設定
DRIVER_PATH = 'C:/Users/mekatana/anaconda3/chromedriver/chromedriver.exe' #CromeDriverの場所
URL = "https://www.google.co.jp/"
# CromeDriverを定義
driver = webdriver.Chrome(executable_path=DRIVER_PATH)
# Googleへアクセス
driver.get(URL)
# 5秒間待機
sleep(5)
# ブラウザを閉じる
driver.quit()from selenium import webdriver
from time import sleepfrom selenium import webdriverはwebdriverのみを使うのでseleniumモジュールからwebdriver関数だけをimportします。
同様にfrom time import sleepはtimeモジュールからsleep関数だけをimportします。
※sleepは後で5秒間待機するために使用します。
# 設定
DRIVER_PATH = 'C:/Users/mekatana/anaconda3/chromedriver/chromedriver.exe' #CromeDriverの場所
URL = "https://www.google.co.jp/"DRIVER_PATHでは
先程ダウンロードしたChromeDriverを保存しているディレクトリを記載します。
URLはGoogleのURLです。
# CromeDriverを定義
driver = webdriver.Chrome(executable_path=DRIVER_PATH)driverを定義することで、ブラウザの立ち上げや閉じるときに
Chromedriverを使用できるようにします。
# Googleへアクセス
driver.get(URL)
# 5秒間待機
sleep(5)
# ブラウザを閉じる
driver.quit()driver.get(URL)でChromeが立ち上がり、指定したURにアクセスします。
sleep(5)で5秒間待機しますので、任意の数字に変更して大丈夫です。
※短すぎるとブラウザが立ち上がる前に次の処理が始まり、エラーが出る可能性もあるので、
3秒以上にするのが無難と思います。
driver.quit()でブラウザを閉じます。
たった数行なので、簡単ですね。
次は必要な情報の取得方法とブラウザ操作方法について解説します。
手順2:要素を取得する
スクレイピングで対象のサイトから情報を取得するには
HTMLコードから、どこに欲しい情報が配置されているか
確認するす必要があります。
スクレイピング練習場(ベータ)というサイトで練習してみます。
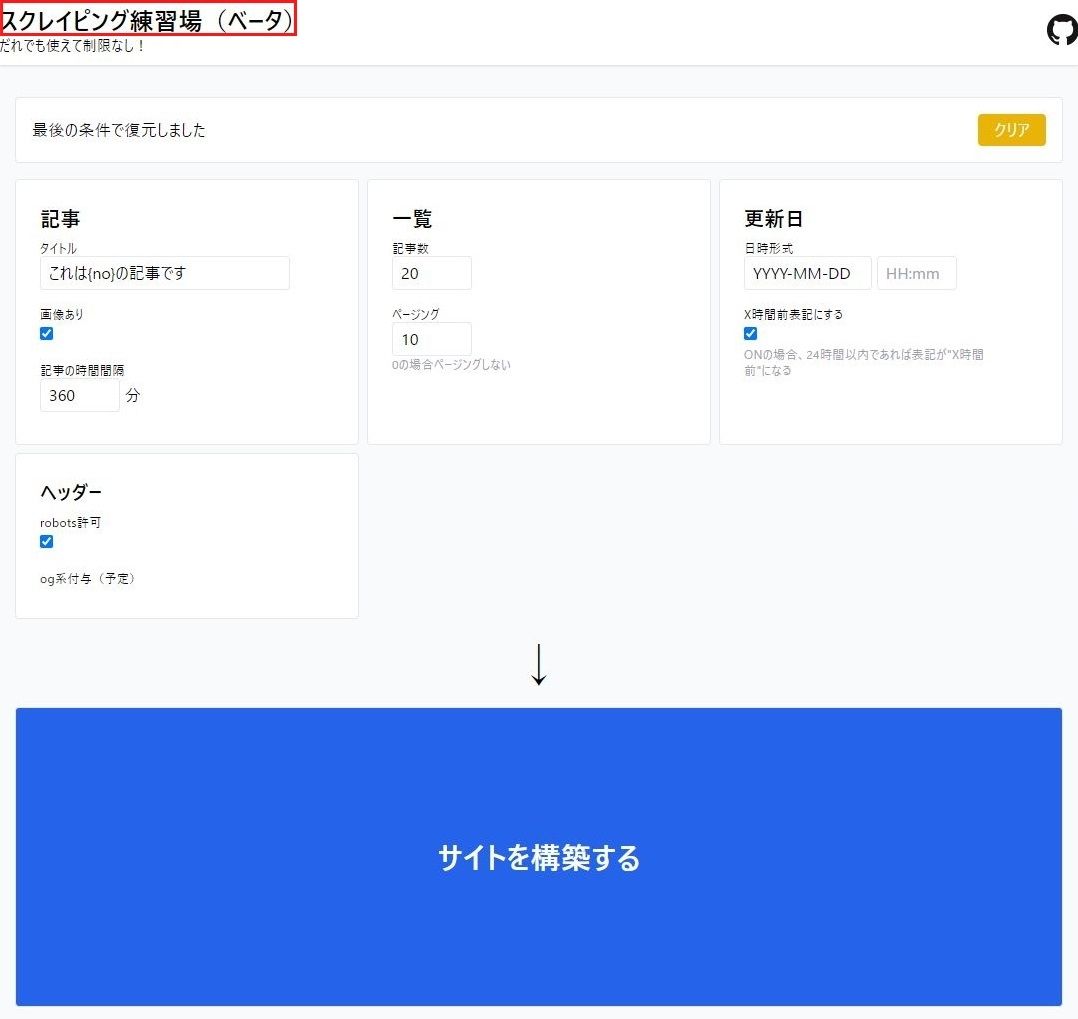
アクセスすると上のような画面が開きます。
試しに赤枠で囲ったタイトル名の『スクレイピング練習場』という
テキスト情報を取得していきます。
HTMLコードを確認するために『スクレイピング練習場』の位置に
カーソルを合わせ、右クリック→『検証』または『F12』を押します。
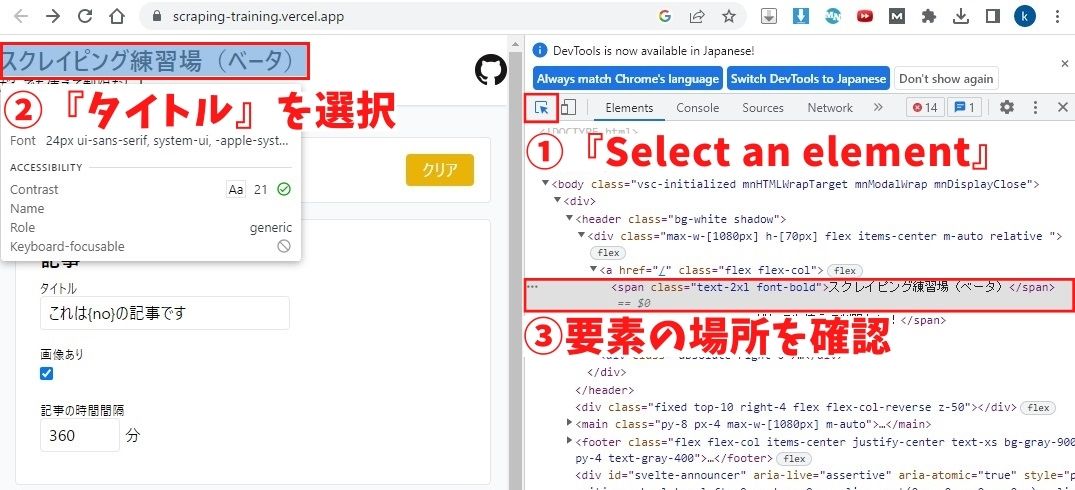
すると上のような右半分にHTMLコードが記載されたページが表示されます。
①『Select an element』→②『タイトル』の順番でクリックすると
格納されている要素の位置を確認できます。
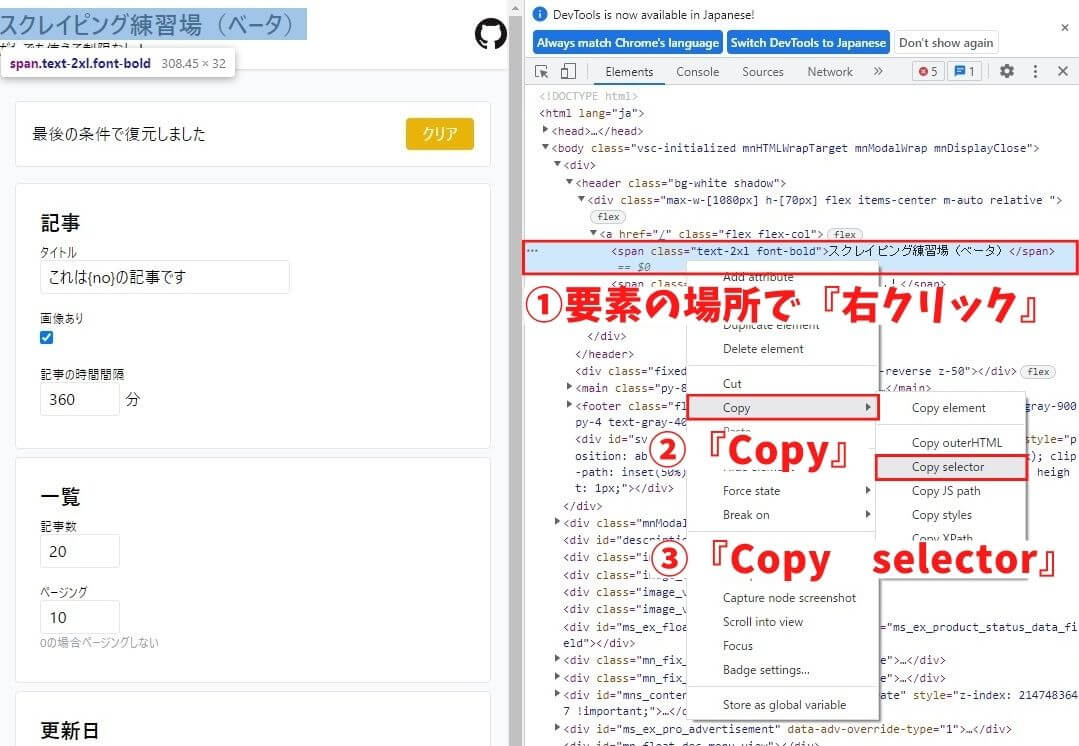
要素の場所が分かれば、その位置で『右クリック』→『Copy』→『Copy selector』を
選択することでCSSセレクタをコピーします。
from selenium import webdriver
from time import sleep
# 設定
DRIVER_PATH = 'C:/Users/mekatana/anaconda3/chromedriver/chromedriver.exe' #CromeDriverの場所
URL = "https://www.google.co.jp/"
# CromeDriverを定義
driver = webdriver.Chrome(executable_path=DRIVER_PATH)
# スクレイピング練習場(ベータ)へアクセス
driver.get(URL)
# 5秒間待機
sleep(5)
# 要素を指定
element = driver.find_element_by_css_selector('body > div:nth-child(1) > header > div > a > span.text-2xl.font-bold')
print(element.text)先程紹介した『Google chromeを起動させてみる』と重複する個所は割愛します。
element = driver.find_element_by_css_selector('body > div:nth-child(1) > header > div > a > span.text-2xl.font-bold')element=driver.find_element_by_css_selector('CSSセレクターを記述')と
記載すればカッコ内の('CSSセレクターを記述')と一致する要素を探します。
なのでカッコ内には先程コピーしたCSSセレクターbody > div:nth-child(1) > header > div > a > span.text-2xl.font-boldを
張り付けます。
print(element.text)print(element.text)で取得した要素をテキスト形式で表示できます。
CSSセレクターの他にもid属性やXPathと一致する要素を
抽出することが出来るので、下の表にまとめます。
| コード | 解説 |
| driver.find_element_by_css_selector("CSSセレクターを記述") | CSSセレクターが一致する要素を探します。 |
| driver.find_element_by_id("idを記述") | id属性が一致する要素を探します。 |
| driver.find_element_by_xpath("XPathを記述") | XPathが一致する要素を探します。 |
| driver.find_element_by_name("nameを記述") | name属性が一致する要素を探します。 |
| driver.find_element_by_link_text("抽出したいテキストを記述") | a要素のテキストが一致する要素を探します。 |
手順3: 要素を操作する
次は要素に対して実行できるコマンドを紹介します。
下のコマンドを使いこなせればIDとパスワードが要求されるサイトでも
自動でログインすることが出来ます。
| コード | 解説 |
| click() | 要素をクリックします。 |
| send_keys("入力したいテキストを記述") | テキストフィールドに任意のテキストを入力します。 |
| clear() | テキストフィールドのテキストを消去します。 |
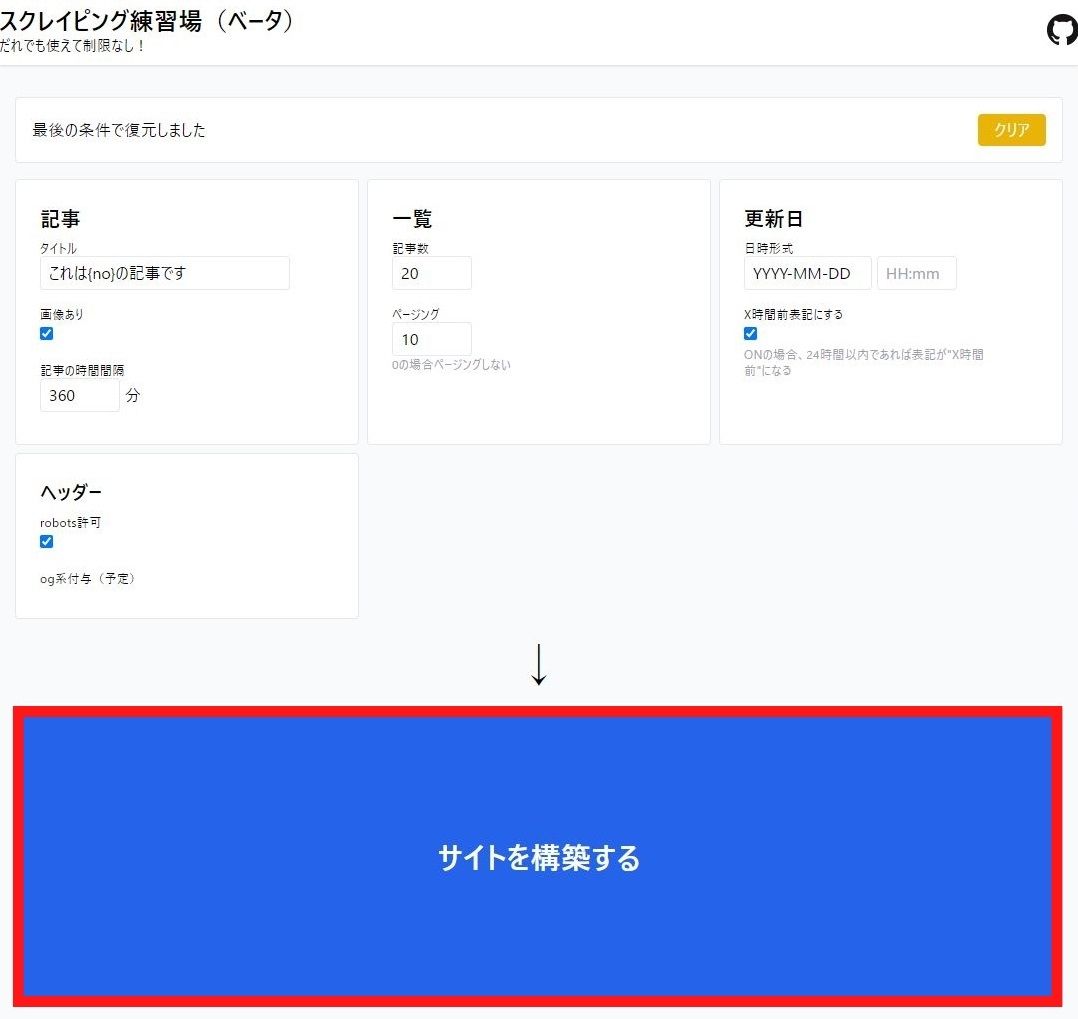
先程のサイトで『サイトを構築する』ボタンをクリックする操作を
Pythonで実行して行こうと思います。
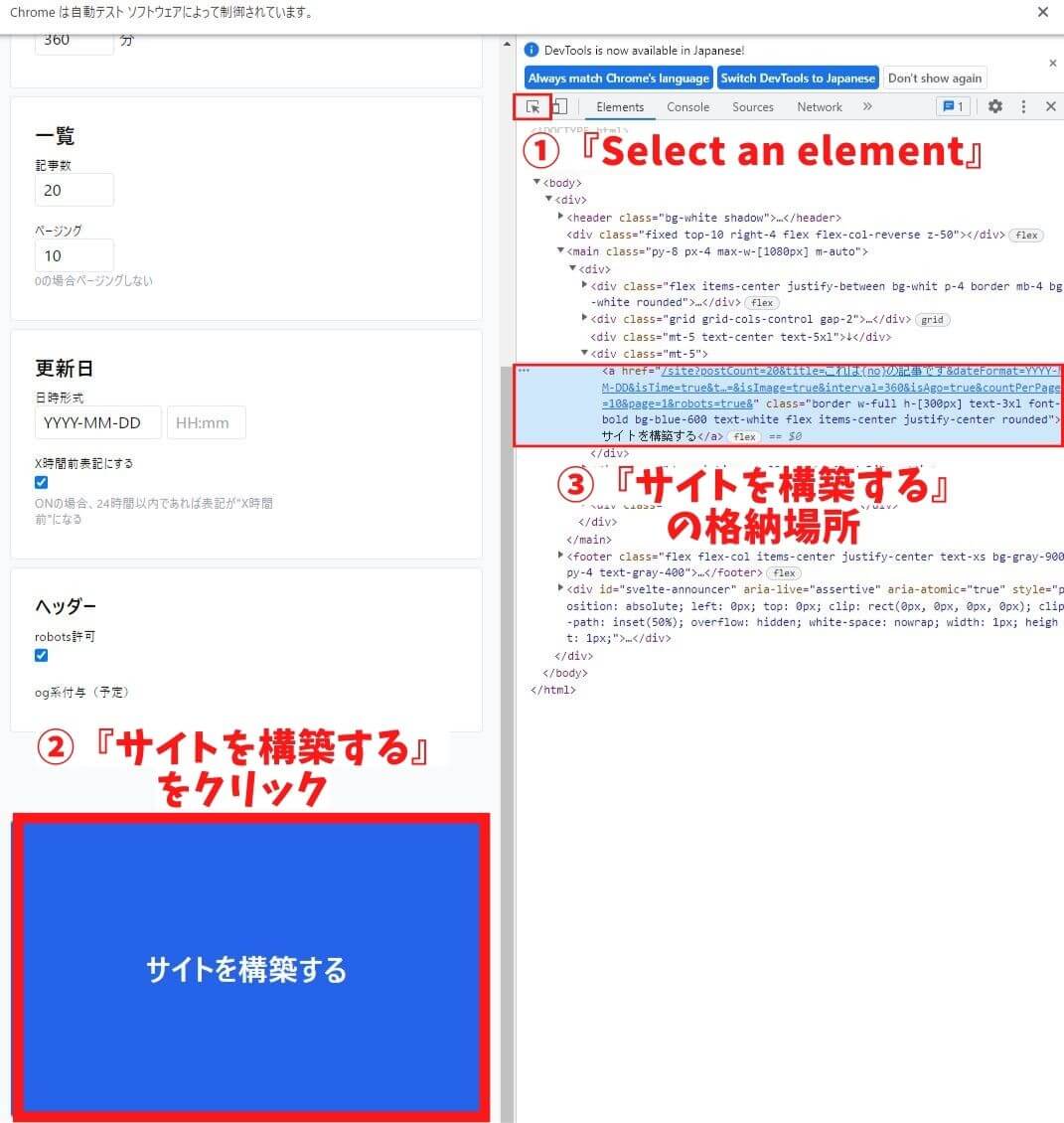
まずは①『Select an element』→②『サイトを構築する』の順番でクリックで
格納されている要素の位置を確認しましょう。
a要素のテキストで記述されているので、driver.find_element_by_link_text("抽出したいテキストを記述")を
使用して要素をクリックします。
『サイトを構築する』をクリックしたいのでdriver.find_element_by_link_text("サイトを構築する")と記載します。
下にコードを紹介します。
from selenium import webdriver
from time import sleep
# 設定
DRIVER_PATH = 'C:/Users/mekatana/anaconda3/chromedriver/chromedriver.exe' #CromeDriverの場所
URL = "https://www.google.co.jp/"
# CromeDriverを定義
driver = webdriver.Chrome(executable_path=DRIVER_PATH)
# スクレイピング練習場(ベータ)へアクセス
driver.get(URL)
# 5秒間待機
sleep(5)
# サイトを構築するにクリック
driver.find_element_by_partial_link_text('サイトを構築する').click()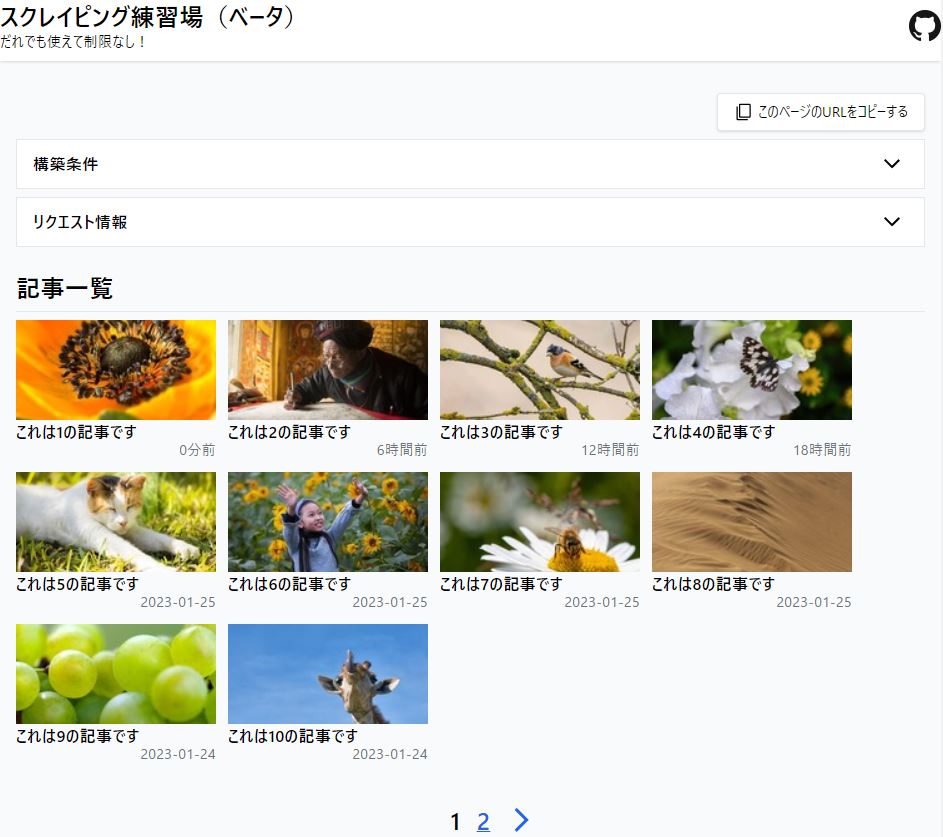
問題なく実行できれば上のような画面が表示されると思います。
③まとめ

seleniumを使ったスクレイピングの方法を解説させて頂きました。
時間を浪費していた手動操作がseleniumを使うことで
自動化が可能なので、生産性が向上するはずです。
面倒な作業はPythonに任せて、余った時間を有効活用しましょう!
しかし、下の記事でも紹介しましたが
次の点に注意してスクレイピングをして下さい。
- 1.利用規約を守る
- 2.Webサイトへの過度なアクセルをしない
- 3.できるだけAPIを使用する
- 4.robots.txtを確認する
-
-
【必読】Pythonでスクレイピング!出来ることと注意点!
以前に『Python出来ること5選』という記事でスクレイピングについて紹介しました。 『Pythonを使えばスクレイピングが可能で、サイトから自動で情報を取得できることは分かったが、他に何かできるの? ...
続きを見る
今回は以上です。
{kind=link}